

Итак, у вас есть решение какой‑то задачи. И теперь вам нужно оценить оптимальность этого решения c точки зрения производительности. Самый очевидный вариант — использовать StopWatch вот таким образом:


Но с этим методом есть сразу несколько проблем:
- Он довольно не точен, поскольку оцениваемый код выполняется только один раз, и на время этого выполнения могут влиять различные сайд-эффекты (жёсткий диск, не прогретый кэш и переключение контекста процессора, другие приложения и т.д.).
- Он не заставляет вас проверять приложение в Production-режиме. Во время компиляции значительная часть кода оптимизируется автоматически, без нашего участия, и это может серьезно повлиять на финальный результат.
- Ваш алгоритм может хорошо показать себя на маленьком наборе данных, но выдать недостаточную производительность на большом (или наоборот). Поэтому, чтобы проверить производительность в разных ситуациях с разными наборами данных, вам придется писать отдельный код для каждой из них.
И какие же у нас есть другие варианты? Как правильно оценить производительность нашего кода? На помощь в этой ситуации нам придет BenchmarkDotNet.
Настройка бенчмарка
BenchmarkDotNet — это NuGet-пакет, который можно установить на любой тип приложения, а затем с его помощью оценить скорость выполнения кода. Для этого нам потребуется всего лишь две вещи — класс, который будет выполнять бенчмаркинг кода, и способ запустить runner для его выполнения.
Вот как будет выглядеть класс для бенчмаркинга в простейшем виде:


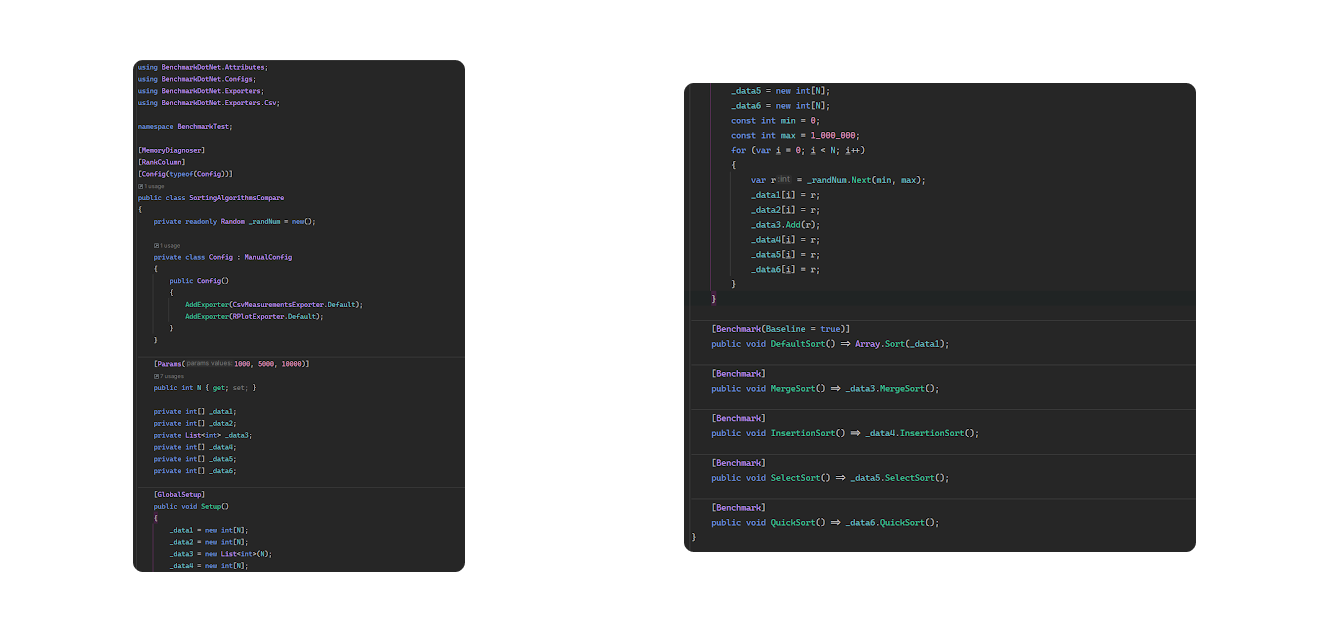
Давайте разбираться, что у нас в этом классе есть. Начнем с атрибутов класса.
MemoryDiagnoser собирает информацию о работе Garbage Collector-а и выделяемой памяти во время выполнения вашего кода.
Orderer определяет порядок вывода финальных результатов в таблице. В нашем случае стоит FastestToSlowest. Это значит, что самый быстрый вариант кода будет первым в результатах, а самый медленный — последним.
RankColumn добавляет колонку в финальный отчёт и нумерует результаты от 1 до Х.
На самом методе у нас добавлен атрибут Benchmark. Он помечает метод, как один из тестовых кейсов, который нужно проверить. А параметр Baseline=true говорит, что производительность этого метода мы будем считать за 100%. А затем уже относительно него будем оценивать другие варианты алгоритмов.
Чтобы запустить бенчмарк нам необходима вторая часть пазла — Runner. С ним всё просто: идём в наш Program.cs (мы всё ещё говорим о консольном приложении) и добавляем одну строчку с BenchmarkRunner:


После этого мы можем собрать наше приложение в Production-режиме и запустить код на выполнение.
Анализ результатов
Если выше мы всё сделали правильно, то после запуска мы увидим, как BenchmarkRunner выполняет наш код множество раз и в конце выдает вот такой отчет:


В отчёте довольно много данных о производительности кода, версии ОС, на которой выполнялся тест, об используемом процессоре и версии .Net. Но основная информация, которая нам интересна, — это последняя табличка. В ней мы видим:
- Mean — среднее время, за которое выполняется наш код;
- Error — ошибку оценки (половина от 99.9 перцентиля);
- StdDev — стандартное отклонение оценки;
- Ratio — оценка в процентах улучшения или ухудшения производительности относительно Baseline — базового метода, который мы считаем за точку отсчёта (помните Baseline=true выше?);
- Rank — ранкинг;
- Allocated — выделенная память во время выполнения нашего метода.
Реальный тест
Чтоб сделать финальные результаты чуть интереснее, давайте добавим ещё несколько вариантов нашего алгоритма и посмотрим, как изменятся результаты.
Теперь класс бенчмарка будет выглядеть таким образом:


Наша задача сейчас — разобраться именно с бенчмаркингом. Сами алгоритмы, которые мы оцениваем, оставим пока в стороне — это тема для следующей статьи.
И вот результат выполнения такого бенчмаркинга:


Тут мы видим что GetYearFromDateTime, который мы взяли за точку отсчёта, — самый медленный и выполняется порядка 218 наносекунд, в то время, как самый быстрый вариант GetYearFromSpanWithManualConversion требует всего лишь 6.2 наносекунды — в 35 раз быстрее, чем оригинальный метод.
Также мы можем видеть, сколько памяти было выделено для двух методов GetYearFromSplit и GetYearFromSubstring, и сколько времени потребовалось Garbage Collector-у на очистку этой памяти (что тоже снижает общую производительность системы).
Работа с различными входными данными
Напоследок я бы хотел рассказать о том, как можно оценивать результат работы своего алгоритма на больших и малых наборах данных. Для этого BenchmarkDotNet предлагает нам два атрибута — Params и GlobalSetup.
Вот как будет выглядеть класс бенчмарка с использованием этих двух атрибутов:


В нашем случае поле Size параметризованное и влияет на код, который выполняется в GlobalSetup.
В результате выполнения GlobalSetup у нас генерируется исходный массив из 10, 1000 и 10000 элементов для выполнения всех тестовых сценариев. Как я и говорил в начале статьи, некоторые алгоритмы могут вести себя эффективно только при большом или малом кол‑ве элементов.
Попробуем выполнить такой бенчмарк и посмотрим на результаты:


Тут мы уже чётко видим, как каждый метод был выполнен с 10, 1000 и 10000 элементами: метод Span лидирует вне зависимости от размерности входных данных, а метод NewArray работает все хуже и хуже с ростом количества данных.
Графики
Библиотека BenchmarkDotNet позволяет анализировать полученные данные не только в текстовом и табличном виде, но и в графическом - в виде графиков.
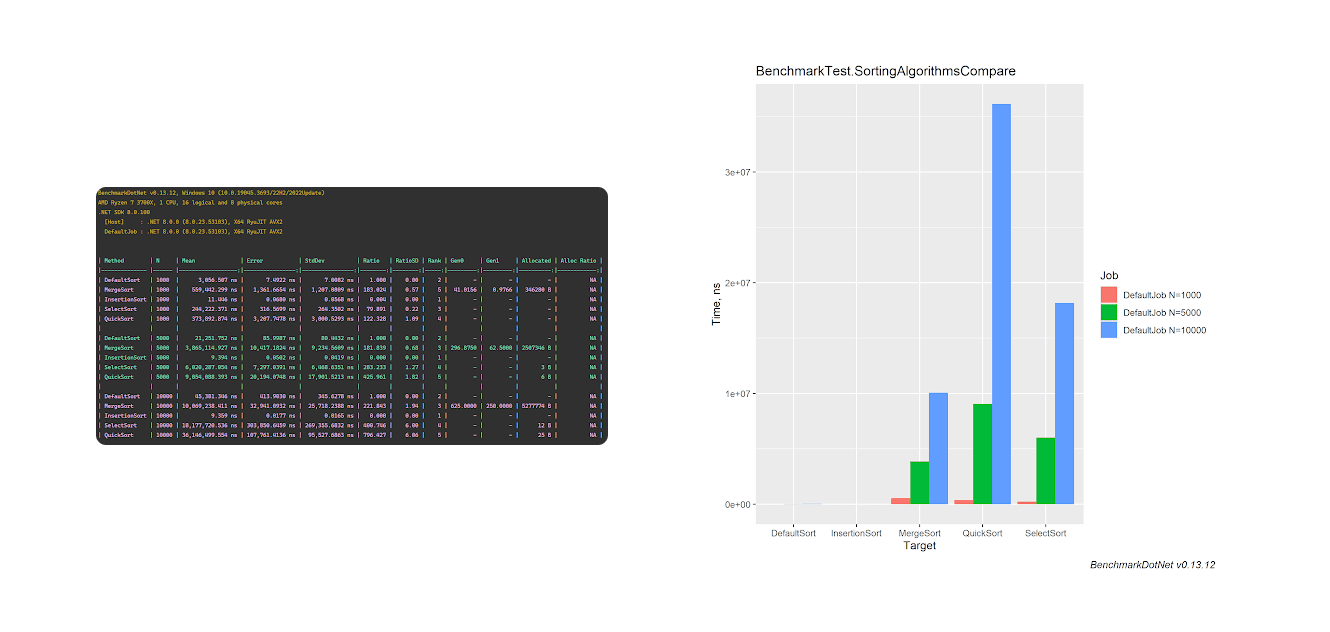
Для демонстрации мы создадим бенчмарк класс для измерения времени работы разных алгоритмов сортировки на платформе .NET8 и настроим его таким образом, чтобы он выполнился 3 раза для разного количества сортируемых элементов: 1000, 5000, 10000. Список используемых алгоритмов сортировки:
- DefaultSort - алгоритм сортировки, используемый по умолчанию в .NET8
- InsertionSort - сортировка вставками
- MergeSort - сортировка слиянием
- QuickSort - быстрая сортировка
- SelectSort - сортировка выбором
В результате работы бенчмарка, мы получили сводный результат в виде таблицы и графика:
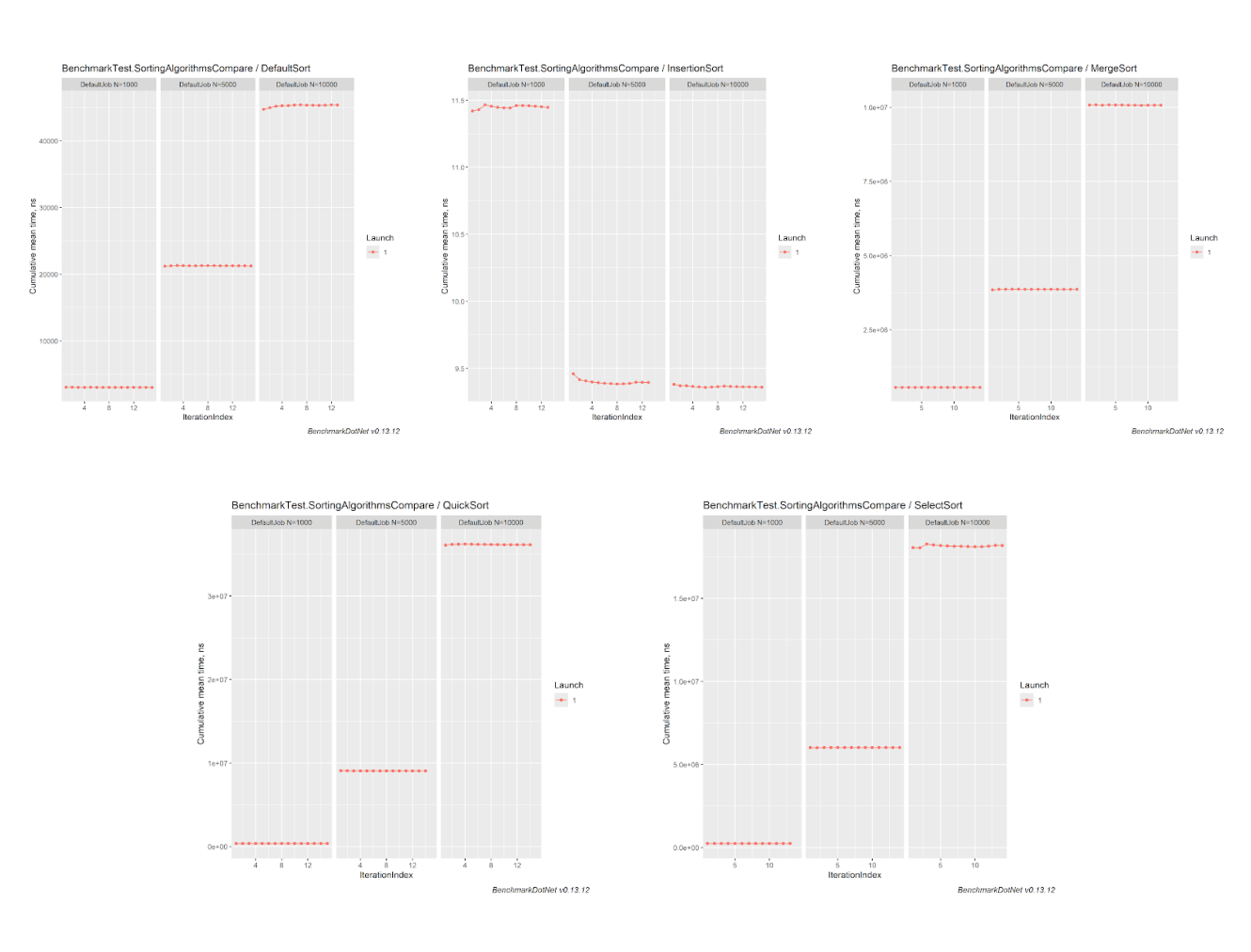
Также BenchmarkDotNet сгенерировал графики по каждому бенчмарку отдельно (в нашем случае - по каждому алгоритму сортировки) в разрезе количества сортируемых элементов:
Заключение
Итак, мы разобрались с основой работы с BenchmarkDotNet и тем, как он помогает нам оценивать результаты своей работы и принимать взвешенные решения — какой код оставить, а какой переписать или и вовсе удалить. Такой подход позволяет нам строить наиболее производительные системы, а значит — улучшать жизнь пользователей.
Автор: Антон Воротынцев
Редактура: Марина Медведева







